探讨篇(四):分布式数据访问解决方案
背景
如果数据在同一个服务的同一个数据库,通过SQL即可查询相对比较简单,但当数据被分布到不同服务不同的数据库中时,访问组合数据的操作就变的比较困难。针对这个问题,本文描述了服务读取不同服务的数据库的几种方法:服务间通信模式、数据缓存模式、数据复制模式、数据共享模式
本文的观点源自我在日常学习与实践过程中的思考,尚处于不断探索和验证的阶段。希望能“抛砖引玉”,激发更多的讨论与交流。让我们共同进步,在探讨与实证中寻求真知。
一、服务通信模式
如果一个服务需要读取它无法直接访问的数据库,只需要使用远程调用比如RPC协议访问另外一个服务即可,这也是很多团队采用的一种方式,如下图:
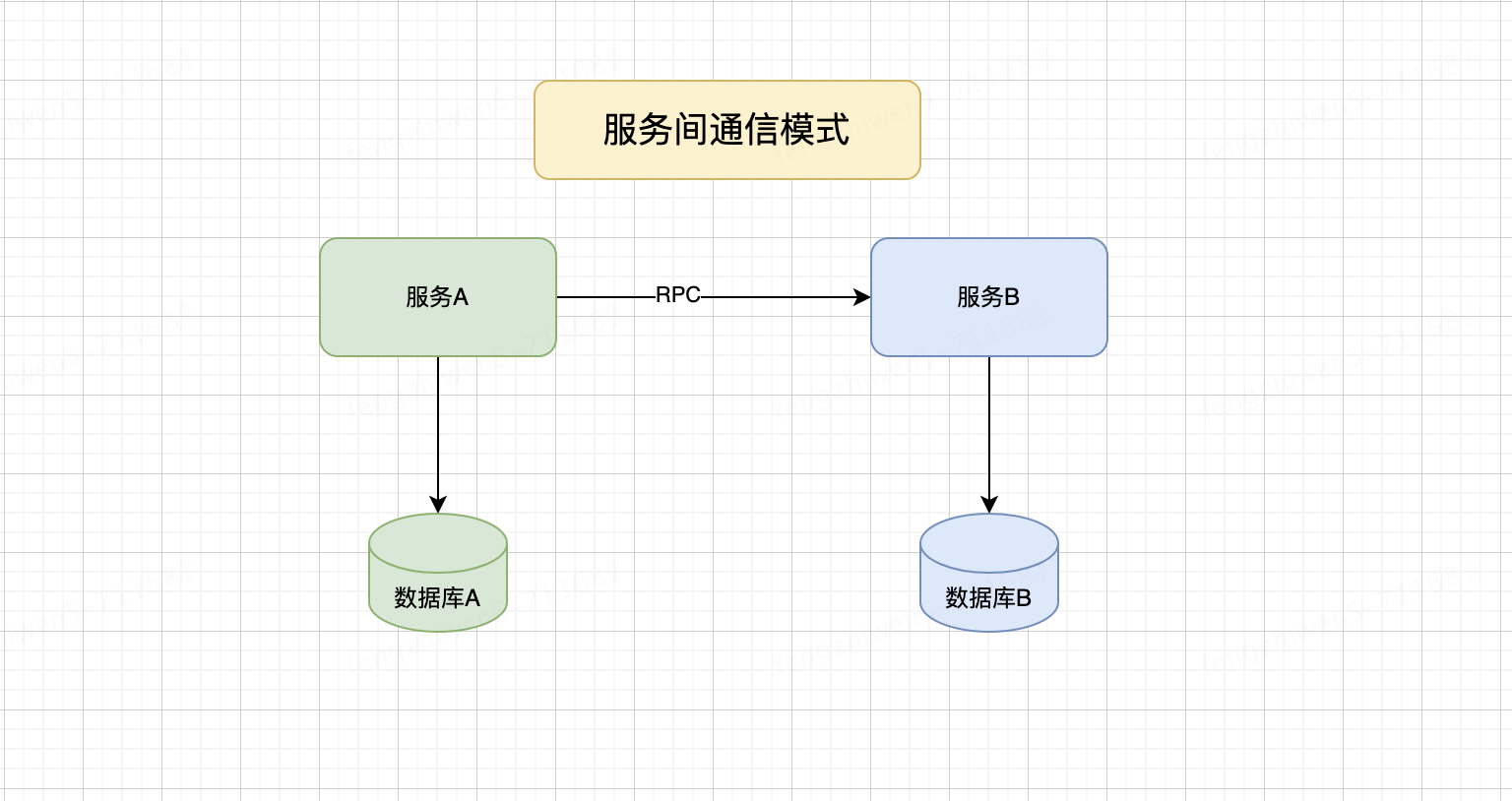
这看起来很简单,但技术充满挑战问题
•首先是数据网络延迟导致服务A性能下降。
•服务之间的耦合,为了满足服务A的访问量,B服务必须随着A服务的流量规模变化而变化。
| 服务通信模式优缺点 | |
| 优点 | 1、没有数据量问题 |
| 缺点 | 1、网络延迟导致性能问题,很常见的TP99跳点,抖动现象 2、可伸缩性和吞吐量问题 3、可用性问题 |
二、数据缓存模式
在上面服务通信的基础上加上缓存,这是很多团队使用的第二种方式。数据保存在每个服务的内存中并持续同步,因此服务拥有完全相同的数据。缓存又分为本地缓存+分布式缓存的组合关系。
1.单机本地缓存,每个服务都包含自己的数据。这种模式对应服务之间无法共享,比如服务启动加载数据到本地缓存。
2.分布式缓存:数据服务之间共享。但这种模式不是有效的复制缓存模式,因为它不能解决服务间通信模式下存在的容错性问题,获取数据从服务调用变成了缓存服务。其次由于缓存数据是中心化及共享的,打破数据所有权,并且可能导致缓存和数据库数据不一致。
以下是每种实现方式优缺点如下:
实现方式一:本地缓存/分布式缓存+RPC远程调用
| 实现方式一:缓存前置(本地缓存/分布式缓存+RPC远程调用),它的核心思想是利用缓存来减少对远程服务的调用次数,从而提高系统的性能和响应速度 | |
| 优点 | 1、减少延迟:通过从本地或分布式缓存中读取数据,可以显著减少对远程服务的调用次数,从而降低响应时间和提高用户体验 2、减轻远程服务压力:缓存可以吸收大量读请求,减少远程服务的负载,特别是在高流量场景下。 |
| 缺点 | 1、数据一致性问题:缓存中的数据可能会过时,如果远程服务的数据发生变化,缓存中的数据需要及时更新,否则可能会导致数据不一致。 2、复杂性增加:缓存策略的引入增加了系统的复杂性,需要考虑缓存更新、失效策略、数据一致性保证等问题。 3、资源消耗:缓存需要占用额外的存储空间,如果数据量很大,缓存可能会消耗大量内存或磁盘空间。 |
实现方式二:通过RPC服务通讯同步推送数据+本地缓存
| 实现方式二:通过RPC服务通讯同步推送数据+本地缓存 | |
| 优点 | 1)实时性:服务B在数据发生变化时立即推送,服务A可以实时获取最新数据。 2)资源利用率高:只有在数据发生变化时才会进行通信,减少了无谓的资源消耗。 3)减少轮询压力:避免了定时任务轮询对服务器的压力。 |
| 缺点 | 1)复杂性:需要在服务B中实现推送逻辑,增加了系统的复杂性。 2)维护成本:推送机制需要额外的维护,包括失败重试、消息顺序保证等 |
实现方式三:通过定时任务worker,服务A通过RPC调用服务B拉数据
| 实现方式三:通过定时任务worker,服务A通过RPC调用服务B拉数据 | |
| 优点 | 1)无需变更现有服务:不需要修改服务B的代码,只需在服务A中添加定时任务。 |
| 缺点 | 1)性能开销:频繁的定时任务可能会对服务A和服务B的性能产生一定影响。 2)延迟性:数据更新可能存在延迟,特别是如果定时任务的频率不高。 3)资源占用:即使没有数据更新,定时任务也会占用系统资源。 4)灵活性差:如果数据更新频率变化较大,固定周期的定时任务可能不够灵活 |
实现方式四:通过异步MQ获取数据
| 实现方式四:通过异步MQ获取数据 | |
| 优点 | 1)异步、削峰、解耦:服务B在数据发生变化时只需发送消息,不需要等待服务A的处理结果。 2)容错性:MQ通常提供消息持久化机制,即使服务A暂时不可用,消息也不会丢失。 |
| 缺点 | 1)复杂性:引入MQ增加了系统的复杂性,需要考虑消息的顺序性、消息丢失、重复消费等问题。 2)延迟:虽然MQ可以提供实时消息传递,但在高并发或者网络问题的情况下,仍然可能存在延迟。 |
缓存模式优缺点:
| 缓存模式优缺点 | |
| 优点 | 1、提高了数据访问性能 2、没有可伸缩性和吞吐量问题 3、良好容错性 |
| 缺点 | 1、大数据量不友好(比如200M),可行性降低 2、高频更新不友好,无法保持完全同步,对于相对静态数据,比较合适 3、缓存数据和服务启动的服务依赖关系。常见机器扩容N台机器,N台同时通过RPC访问服务B,导致服务B流量暴涨,并且写分布式缓存流量暴涨(N台*每台缓存大小) 4、适合一致性较弱的场景,缓存一致性问题,可能导致数据陈旧 |
三、数据复制模式
在数据复制模式中,表之间会进行数据复制,也就是在数据库A冗余数据库B数据。这样可以确保服务A直接访问数据库A获取到数据库B的数据。可以通过很多种实现方式:
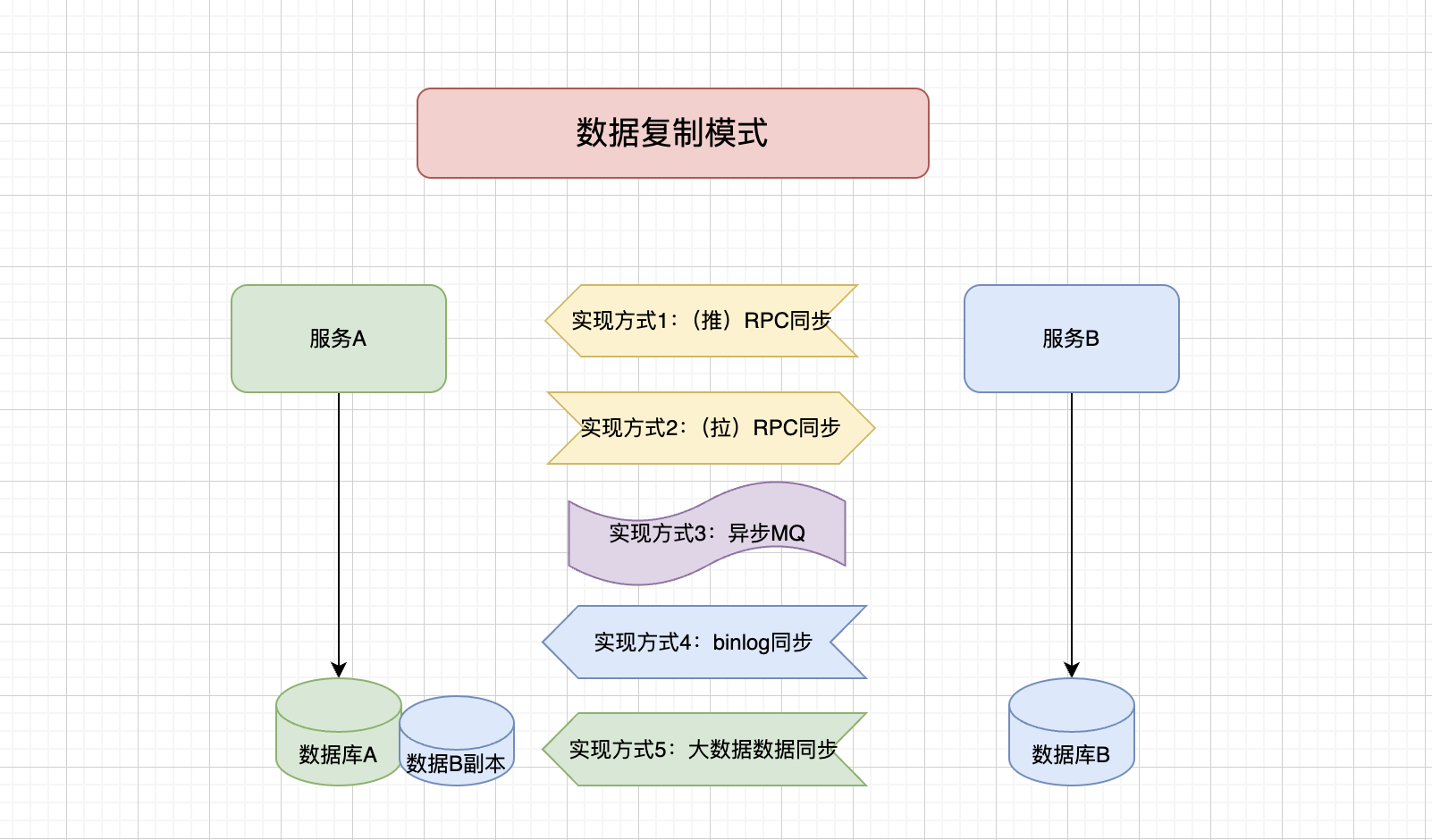
但这同样存在如下问题:如何管理数据所有权?到处都有这种数据,数据一致性问题
| 实现方式四:binlog同步,需要注意binlog数据量 | |
| 优点 | 1)实时性:Binlog可以捕获数据库的实时变化,使得数据同步具有较低的延迟。 |
| 缺点 | 1)性能影响:虽然Binlog的开销相对较小,但在高并发写入的场景下,Binlog的生成和处理仍然会对数据库性能产生一定影响。 2)依赖数据库:这种同步方式依赖于MySQL的Binlog功能 |
这种方案改善了上面服务通信的性能,容错性,可伸缩性问题。某些场景可用,比如聚合,报表或者其他不适合高性能需求,高容错性的时候
| 数据复制模式优缺点 | |
| 优点 | 1、良好的数据访问性能 2、没有可伸缩性和吞吐量问题 3、没有容错性问题 4、没有服务直接依赖 |
| 缺点 | 1、数据一致性问题 2、数据归属权问题 3、需要数据同步 |
四、数据共享模式
如果上面的3种方式都不行,那可以用兜底方式,用创建数据领域,把数据组合到共享的数据库,让服务A和服务B都能访问。
服务之间完全解耦,解决了可用性依赖,响应性,吞吐量和可伸缩性问题
| 数据库共享模式优缺点 | |
| 优点 | 1、良好的数据访问性能 2、没有可伸缩性和吞吐量问题 3、良好容错性 4、无服务依赖 5、数据保持一致 |
| 缺点 | 1、数据所有权治理 2、数据访问安全 |
总结
1.通过本文的探讨,大家可以更全面地了解分布式数据访问的挑战和可能的解决方案
2.每种模式都有其优势和不足以及应用场景,本文旨在通过对比分析,为实际应用中的选择提供指导。
3.如果以上文案有问题或者还有更好的方案,欢迎评论区留言补充完善,谢谢
审核编辑 黄宇
继续浏览有关 大数据 的文章
猜你喜欢
华为开发者大会2025(HDC 2025)亮点:华为云发布盘古大模型5.5 宣布新一代昇腾AI云服务上线

6月20日,华为开发者大会2025(HDC 2025)在东莞篮球中心隆重揭幕。本次大会包含主题演讲、峰会、专题论坛、互动体验以及数百场面向开发者的特色活动。华为携手各领域客户及伙伴,全面分享了HarmonyOS、昇腾AI云服务、盘古大模型...
Tag:大数据低成本数据采集方案:老旧设备联网赋能工业物联网系统与实时数据分析

一、 背景:小微企业的老旧设备改造困境 工业4.0与物联网浪潮下,传统老旧设备面临升级压力。然而,对于众多小微企业而言,设备整体换代成本高昂、风险不可控,导致大量老旧设备仍在服役,成为其数字化转型的瓶颈。这些设备普遍存在:...
Tag:大数据电缆隧道在线监测装置如何实现电缆隧道的智能运维?
电缆隧道在线监测装置是一款集成传感器技术、通信技术、数据分析技术的综合系统,可实现电缆隧道的智能化、科学化运维管理。系统应用不仅是保障电力传输安全,同时也可以推动电网运维向“主动预防”模式转型。 系统的应用优势体现在多个方面,如实时性...
Tag:大数据服务器数据恢复—linux操作系统云服务器数据恢复案例

顶层设计出炉,数据基建迎利好!

国家将要以数据基础设施建设为契机,培育一批数据基础设施相关企业。 政策密集助力数据基建 1月6日,国家发展改革委、国家数据局、工业和信息化部印发《国家数据基础设施建设指引》(下文《建设指引》)。聚焦数据基础设施的概念、发展愿景、建设目标等内...
Tag:大数据