电商数据、影视作品、网络文学……都是帮助AI成长的营养 喂饱人工智能,浙企有“料”
OpenAI又“炸场”了。近日,具备“听、看、说”出色本领的“GPT-4o”亮相,新模型能够处理50种不同的语言,还能读取人的情绪。仅仅两日后,OpenAI宣布与社交网络Reddit建立合作伙伴关系,这个被称为“美国贴吧”的平台内容,将被引入ChatGPT和其他产品中。
将两条信息连起来看,当大众惊叹于AI的训练速度时,不少业内人士已嗅到一丝危机:全能,意味着需要更强大的语料库来训练AI,而优质的AI语料已经越来越稀缺。
AI语料,简单来说,就是用于训练和优化人工智能模型的数据集合。根据人工智能研究机构Epoch的分析,在2026年前,科技公司很可能会耗尽互联网上所有的高质量数据。
数字经济发达的浙江,是国内优质AI语料资产库存区域之一。如何充分发挥AI语料的存量优势?应对AI语料短缺的预期,浙江如何先发布局?
在AI大模型技术路径逐渐清晰、各方抢占算力迭代产品的当下,越来越多的业内人士重新将目光投向驱动模型生成的“燃料”——语料。
“大模型就像初生的孩子,教它学习、成长的课本就是AI语料,编纂教材的过程就是构建语料库的过程。”杭州城市大脑有限公司总经理申永生形象比喻。目前,我国10亿参数规模以上的大模型数量已超100个,每一个都“嗷嗷待哺”,更优质更丰富的语料资源,才能支持其更新迭代。未来,AI语料将是行业争夺的新战场。
城市大脑即是通过“消化”“吸收”优质语料,形成分析研判能力,不断提升社会治理与服务能力。“一方面,我们从各类用户反馈端获取语料,比如12345、留言箱、办事窗口等信息,通过学习百姓与‘端’的互动数据,让城市大脑更智能;另一方面,政府信息公开的数据也是语料来源之一,基于这类天然可抓取的数据,我们能提供汇总更多公共服务的信息。”申永生介绍。
尽管有双重途径获取语料,但存量资源短缺的事实也摆在眼前。众多大模型“饥肠辘辘”,但面对海量数据却不能“饥不择食”,因为原始数据需要经过层层标注与筛选,才会变成有价值的语料。
中文优质语料的供给,更迫在眉睫。“中国大模型发展要获得突破,必然依赖于中文优质语料库的建立。”申永生分析,目前多数大模型的数据训练多以英文为基础,如在ChatGPT的训练数据中,英文语料占比超92.6%,中文语料占比却不足千分之一。语言的壁垒、流通的受限,使得中文优质语料在业内成为“香饽饽”。
在浙江,优质AI语料的存量优势明显。
以阿里巴巴为代表的电商企业,拥有产品材料、客户互动数据、电商直播素材等大量电商相关AI语料;商汤科技、海康威视等企业,在AI视频识别方面积累了大量可用数据;众多MCN公司拥有海量短视频素材;杭州的网络文学作家村、之江编剧村等则是优质文本语料的储藏地……
眼下,拥有语料“富矿”的浙企,已在暗自发力,利用自身拥有的语料资产,开发和优化自研工具库,拓展行业AIGC工具的应用场景。
作为国内电视剧行业的龙头公司,华策集团正在探索将语料数据变为创作生产力。企业拥有超5万小时的影视素材,以及影视剧本、IP评估报告、宣发材料等文本素材,这些都是制作AI语料的原料。基于专业语料,华策集团AIGC应用研究院训练并开发了一整套“影视剧本智能创作辅助系统”,集成了编剧助手、剧本评估、视频检索等多项功能。

“影视级别语料不仅质量高,而且具有中华传统文化特色,用影视语料训练出的大模型克服了海外大模型国外元素多或质量低下的问题。”华策集团AIGC应用研究院副院长沈雄介绍,在高质量语料的基础上,华策自研的“有风”大模型3分钟内就能完成一部IP作品的初筛,30分钟内能精确评估百万字作品内容,这样的体量过去依靠人工需要一周以上的时间,极大地提高了工作效率。
另一家金融浙企同花顺,拥有企业十几年积累的自身数据及市场的公开金融数据,这些数据涵盖了股票、基金、债券等各种证券类型,囊括了财经领域的公告、新闻、研报等九大类语料,预训练金融语料达到了万亿级Tokens。
今年1月,同花顺发布大模型问财HithinkGPT,成为市场上唯一集金融查询、投资咨询、资讯分析以及事件点评于一体的大模型。“专业的AI语料促进了大模型技术和业务的创新,为金融领域提供了研究和开发的基础资源。”企业相关负责人表示,目前,同花顺AI开放平台可面向客户提供智能金融问答、智慧政务平台、数字虚拟人等多项AI产品及服务。
随着AI语料价值凸显,众多问题也浮出水面。今年初,《纽约时报》起诉OpenAI及其投资人微软公司,指控二者未经授权使用其数百万篇文章训练大模型,打响了语料维权“第一枪”。
采访中,不少企业表示,目前企业的语料数据主要用于开发和优化自研工具库,尚未与其他公司达成商业合作。“语料数据产品交易潜力巨大,但存在诸多不确定性,企业的担忧在所难免。”申永生分析,除了版权盗用的法律问题和训练模型存在的道德风险、价值观隐患,AI语料真正走向市场,最根本的是建立健全交易平台和机制。
“这正是浙江抢占先机的重要方向。”申永生认为,浙江已在数字经济领域占领高地,在语料储备较充足的基础上,可以从建立数据交易所开始尝试,探索一条语料交易的新路。对此,浙江已下出“先手棋”。2022年,中国(温州)数安港开园,直面数据不能共享、不敢共享、不愿共享“三不”难题,在全国数据要素市场化改革中探路先行。
两年来,改革通过构建数据安全合规体系、司法保障体系等方面数据基础制度,确保流通交易合规,破解“不敢共享”难题;通过构建数据金库、联合计算平台、安全可信数据空间、公共数据授权运营域等数据基础设施,为流通交易全过程提供技术保障,破解“不会共享”难题;通过构建从数源归集到数据产品流通交易的全链条产业生态,营造成熟的数据市场,破解“不愿共享”难题。
开园至今,数安港已落地企业311家,发布数据产品344个,成交6.6亿元;与国内七大数交所签署战略合作协议,设立了10个国家级数据安全实验室与创新基地。“随着数据交易市场的开放与完善,其训练出的大模型将为社会提供更精细化的服务,浙江数字经济将迎来新的飞升。”申永生说。
猜你喜欢
AI时代下的全新画质体验,海信电视E7N做到了么?

在人工智能技术飞速发展的今天,AI已经不仅仅是一个概念,而是开始真正融入并改变我们的日常生活。在电视行业,AI技术的应用正带来前所未有的画质体验。海信电视E7N,作为AI时代的先行者,通过其独特的技术优势,正在重新定义电视画质的新标准。...
Tag:人工智能国家数据局首次发布,城市数字化转型加快!锑、超硬材料出口管制即将落地(附股)

通信行业周报:三折叠屏引领消费电子潮流,AI+终端发展有望提速

(以下内容从上海证券《通信行业周报:三折叠屏引领消费电子潮流,AI+终端发展有望提速》研报附件原文摘录) 周行情 行情回顾:过去一周(2024.9.2-9.8),上证指数、深证成指涨跌幅分别为-2.69%、-2.61%,中信通信指数涨跌幅为...
Tag:人工智能从“可用”到“好用”,百度智能云如何做大模型的“超级工厂”?
存储2024H1财报:行业上行带动高增长,新品搭上AI成驱动力
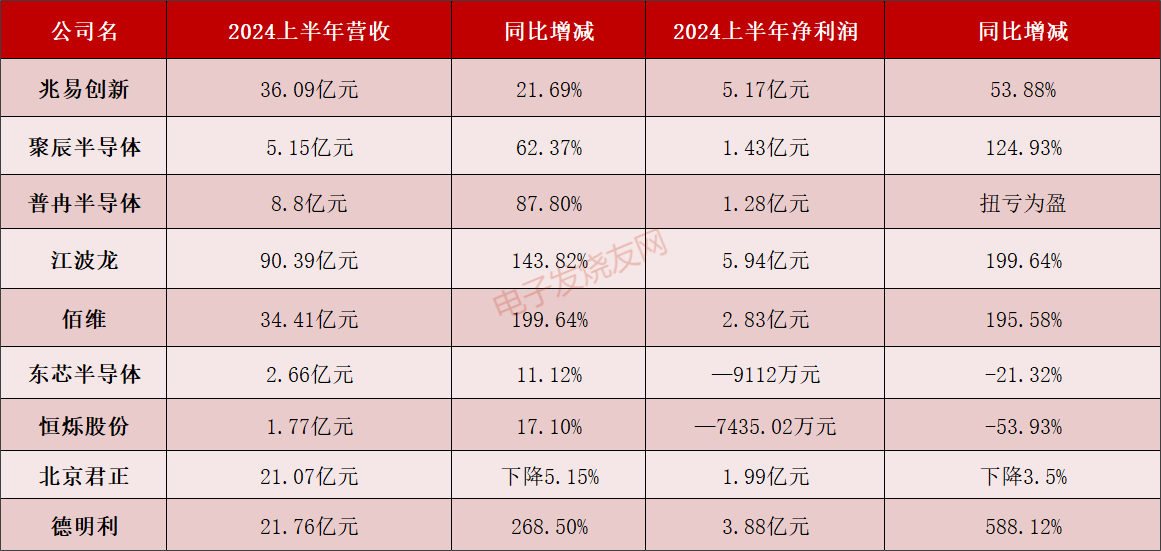
电子发烧友网报道(文/黄晶晶)自2023年第三季度开始,存储产业逐渐由之前的厂商亏损、大幅减产、需求不振等低迷行情,转变为步入复苏的上行周期。在我们之前跟踪的2023年第四季度以及2024年第一季度财报中已显现出这种向好的趋势。最近,国内...
Tag:人工智能