聚焦大模型:原理、进展及其影响,CMF专题报告发布

本文字数:8945字
阅读时间:23分钟
9月9日,由中国人民大学国家发展与战略研究院、经济学院、中诚信国际信用评级有限责任公司联合主办的CMF宏观经济热点问题研讨会(第73期)于线上举行。

本期论坛由中国人民大学一级教授、经济研究所联席所长、中国宏观经济论坛(CMF)联合创始人、联席主席杨瑞龙主持,聚焦“大模型:原理、进展及其影响”,来自学界、政界、企业界的知名人工智能专家、经济学家黄铁军、漆远、沈建光、文继荣、李超、刘陈杰联合解析。

论坛第一单元,中国人民大学高瓴人工智能学院执行院长、信息学院院长文继荣代表论坛发布CMF中国宏观经济专题报告。

报告围绕以下两个方面展开:
一、 大模型的背景和原理
二、 大模型的飞速发展及趋势
三、 大模型的深刻影响
一、大模型的背景和原理
2022年11月30日,ChatGPT横空出世,引发了一轮大模型热潮。ChatGPT是由OpenAI公司开发的语言模型,它能通过大规模的语料库学习语言规律,从而生成与人类语言相似的输出。长期以来,学术界一直都在研究大模型,而ChatGPT之所以能够引发这次热潮,是因为OpenAI将其ChatGPT做成了一个对话机器人,以人机聊天的形式发布,这让除了专业人士之外的普通人也可以接触到大模型。通过与其交互,大家发现它展现出了惊人的对话能力,拟人程度非常高,从而引发了全社会的关注,发布后两个月用户就达到了1亿。
从技术上来说,它是人工智能里程碑式的突破。比尔・盖茨、马斯克等都对它进行了高度评价,比尔・盖茨认为它的重要性不亚于互联网,而我个人认为它远比互联网更重要。
1、ChatGPT大模型的特点
1)知识广博
ChatGPT一般是在万亿级的语料上训练出来的,它看到过很多不同领域的文章,所以上知天文、下知地理,不仅能写文章,还能写代码。
2)有条有理
此前的很多大数据模型都难以将知识整合起来完成任务,而ChatGPT能够将广泛的知识整合起来,针对具体问题形成答案,甚至展示出一定的推理能力,这是非常惊人的。
3)善解人意
ChatGPT基本上已经解决了语言理解的问题,能够准确理解用户意图,这在人工智能的发展史上是非常困难的事情。
4)交互能力强
尤其是在多轮对话或者较长的对话序列中,ChatGPT能聚焦对话的主题,不走神。
总之,从技术上来看,ChatGPT的以上四个能力都是人工智能发展史上的重大突破。学界长期悬而未决的关键问题在ChatGPT,包括最近的GPT-4等大模型中已经得到了相当大程度的解决,这种技术上的重大突破必然会产生深刻的影响。
之所以说ChatGPT的意义深刻,是因为语言在人类文明史上扮演着极其重要的作用,甚至可以作为人类区别于其他动物最重要的属性。有了语言,文明才能传承,人和人之间才能交流,形成深度的思考。21世纪最伟大的哲学家维特根斯坦在语言上就有很深的造诣,他曾说过,语言的边界就是世界的边界,甚至是思考的边界,这与当今的大模型发展有一些惊人的吻合。计算机鼻祖图灵在早期的一篇著名论文中提出了“图灵测试”,它通过人机对话的方式,判断一个系统是否具有人工智能的标准。由此可以看出,语言始终在人类思想史,以及人工智能的历史上占据着核心的地位。
在很多领域,尤其是人工智能领域一直有一个假设,即世界知识和人类的认知能力是蕴含在人类语言中的。这是一个很强的假设,如果这个假设成立,就会产生三个问题:
1)是否可以对人类自然语言进行建模?即能否用一个模型来表述这样的语言?不仅是语言本身的语法语义,还有其中蕴含的知识,甚至是人类的逻辑思维能力和思想,能否用一个模型来表述?
2)如果上述语言模型能够实现,是否可以将其作为世界知识模型?
3)这样的语言模型是否具有人类的认知能力和思考能力?

沿着这样的思路,人工智能领域的专家们在过去几十年不断地进行探索,希望构建出这样的语言模型,它本质上是对人脑的反向工程。左边是人脑,它本身是一个复杂的神经网络。由于人脑太过复杂,我们难以弄清其中的结构,但可以通过观察它的生成物,比如语言、文字等,通过大量反向工程训练出一个人工的神经网络,也就是语言模型。
如果人工神经网络生成的语言和人脑生成的语言非常接近,就可以认为它是人脑神经网络很好的数字模拟体。ChatGPT的横空出世证明了这是一条可行的路径,它也对上述三个问题给出了相对肯定的回答。因此,从科学史上来说,这具有重要的意义,即我们可以做出一个和人脑非常接近的人工大脑。它具有和人类非常相似的语言能力,同时又蕴含了世界知识和人类的认知能力。
2、语言智能的探索历程
语言智能的探索历程始于上世纪50年代,最早的是符号规则,即给定一组人工设定的规则,通过对数据应用这些规则来模拟自然语言的理解;随后是统计机器学习,即在人工标注的语料上进行特征工程,训练机器学习一些小模型;然后是神经网络,用神经网络在大量数据上训练,学习更灵活的模型。2016年前后,出现了预训练语言模型,即通过自监督的方式,用大量语料来训练模型;到2022年,进入了超大规模语言模型阶段,它也是预训练模型,但规模很大,并且出现了很多新能力。
在语言智能的发展过程中,模型功能越来越强,泛化能力越来越好,任务求解能力也越来越强。
1)统计语言模型――大模型的基础
统计语言模型本质上是从语言中自动学习出一个统计模型,比如它可以通过统计语言之间的关系,计算一句话出现的概率。这个模型相较基于规则的方法来说有巨大的进步,但它还是存在很多问题,比如当词越来越多,窗口越来越大的时候,会出现组合爆炸;泛化性差,字词之间没有关联;最重要的是数据算力不够,因此无法用这种方法做大规模的统计模型。
2)生成式语言模型
GPT系列使用的是一种生成式语言模型,英文叫做Generative Language Model。本质上,它也可以看成是一个统计模型,但在做法和技术上有了巨大的飞跃。它进行了一个“文字接龙”的任务,比如把一句话的最后一个词盖住,让模型去猜这个词是什么,如果猜不准就调参数,直到它能准确猜出这个词。如果是在很多语料上做类似的预测,模型的预测能力就越来越强,到最后,无论是词语还是句子的组合,它都能猜出下一个是什么词。
引入注意力机制解决了长程上下文依赖问题。如果大模型能够看到尽可能多的词,它的准确率就会大大提升,但计算量会非常大。通过引入注意力机制,不仅能够解决长程上下文依赖的问题,同时也能提高计算效率,模型的大小也能得到控制。
此外,我们采用了多层神经网络抽象解决泛化的问题。深度学习就是指神经网络结构的层次,通过层层抽象学习到更高层的语义,对概念进行泛化,这也是一项进步。
最重要的是,我们有海量的数据和巨大的算力。现在的大模型基本是在万亿级的Token上面训练得出的,人一辈子都不可能看这么多的词、句子和文章。要在如此大的数据量上训练这么复杂的模型,就需要巨大的算力支持。过去这些年,算力尤其是GPU为代表的算力,有了巨大的进展。技术、数据算力的共同进步,使得我们今天能够造出一个如此庞大的模型。
3)掩码语言模型
掩码语言模型和生成式模型的做法差不多,以BERT模型为代表,它不是做“文字接龙”,而是做“完形填空”。比如一个句子随机遮掉一个词,让它根据上下文猜出这个词是什么,通过大量的语料训练提高准确率,最后训练出这样一个模型。
二者的区别在于,掩码语言模型是根据上下文进行猜测,而生成式模型只能根据上文进行猜测。生成式模型之所以能够胜出,是因为其一,它的生成过程更接近自然生成的过程;其二,当语料数目很大时,只看前文的效果不见得比看上下文的效果差。

掩码模型最早是Google走的路线,生成式模型是OpenAI公司走的路线。现代模型是自2013年Google提出Word2Vec后发展起来的,标志性事件是2017年Google提出了Transformer,这是当前所有大模型的支撑性神经网络架构,在此基础上,产生了BERT,此前这条路线一直占据优势。
OpenAI从2018年开始做GPT系列,2019年推出GPT2,当时的效果不如Google。2020年,OpenAI提出了GPT3,这是世界上首个千亿模型,有1750亿的参数,把参数一下子提高了几个数量级。这个模型展现出了惊人的能力,此后这条路线就占据了上风。随后,OpenAI在2021年、2022年逐渐引入代码思维链,WebGPT引入了搜索能力,InstructGPT能理解人类指令,去年推出的ChatGPT引入了对话能力,引起了这次的热潮。
Google很早就开展了大模型的研究,诸如Transformer这种核心技术,甚至包括思维链的设想都是Google提出来的。但是OpenAI走得更坚定,在工程化方面做得更彻底,所以今天占据了优势。
3、ChatGPT大模型的优势
1)法宝一:“大”
通过大数据、大算力得到一个大模型。GPT-3是1750亿参数量,据说训练一次消耗会1200万美元。GPT-3.5、GPT-4的参数量更大,训练的成本也更高。
模型的参数可以类比为人脑的神经元。神经元之间有连接的突触,人脑大概有800-1000亿个神经元,它们之间的连接突触数目在100万亿。大模型的参数可以看作神经元之间的连接,也就是突触的量级。人脑有100万亿,而大模型达到了千亿级,和人脑只差三个数量级,GPT-4已经达到了1.8万亿,仅相差两个数量级。按照计算机学科的发展趋势,再过几年,大模型就可能达到人脑百万亿级的规模。随着模型参数量的增长,人类认知中的很多能力就会“涌现”出来。
2)法宝二:思维链/逻辑训练
为了让模型具有逻辑性,能够把知识组合起来完成复杂任务,就要对它进行进一步训练。Google在2022年提出的思维链(Chain of Thought)思想,即通过告诉模型思维的全过程,让其形成自己的思维链。当训练到一定程度时,甚至不用再给它例子,而是让其“一步步思考”,就能激发模型的思维链。
还有一种猜想是思维链能力来自代码的能力,代码就是一个思维链的过程。由于写程序解决某个问题需要一步步通过逻辑结构完成,因此模型也能学到这个思考的过程。
3)法宝三:价值观对齐

当大模型的能力强大到一定程度时,若不对它进行价值观驯化,而是放任其发展,这是非常危险的。OpenAI聘请了很多人,通过数据标注对模型进行了价值观对齐,学术上将其称为RLHF,也就是基于人类反馈的强化学习。当给出一个问题时,用人类价值观写出引导模型的标准答案,并让模型基于答案强化学习,最终使其能够遵循人类的价值观回答问题。
4)法宝四:数据闭环+系统工程
大模型是一个特别大的系统工程,涉及数据收集、数据清洗、指令标注、模型训练中参数的选择、数据配比、价值观对齐等方方面面的工作,需要大量的数据和算力支撑。另一方面,OpenAI收集了很多数据反馈形成闭环,可以进行快速分析迭代。
4、ChatGPT的不足
ChatGPT仍然存在着很多不足,比如,由于训练的成本太大,无法实时纳入新知识;尽管知识面广泛,但深度还不够;推理计算能力不足,尤其是在面对一些复杂的逻辑推理和数学问题时还存在很大的问题;只支持文本生成,算力消耗巨大等。
对于计算机科学领域来说,这些不足都是工程问题,是能够通过努力解决的。当前已经不存在不可逾越的理论障碍。在ChatGPT大模型发布前,人们对于如何让模型具有逻辑思考和推理能力是一筹莫展的,而ChatGPT,尤其是GPT-4向我们展示了它具有这样的能力,这给了我们无穷的信心。
二、大模型的飞速发展及趋势
ChatGPT发布后的大半年内,大模型经历了超乎想象的发展速度。
从技术角度来说,大模型在以下几个重要方面都有了很大进展:增强实时性和真实性;支持多模态;扩展知识和技能;连接物理世界;改进复杂推理;自主智能体,它可以自主完成一切事情,包括做规划、调用外部工具等;支持个性化;提高训练和推理的效率,由于推理的成本非常高,提高大模型的训练和推理效率是极其重要的。
以扩展知识和技能为例,2月份,Meta发表了一篇关于Toolformer的文章。语言模型中有一个基本假设,即世界知识和人类的技能都蕴含在语言中。现在认为大部分情况下是这样的,但有部分人类知识和技能自然语言是不擅长表达的,比如算数。对于这些难以从自然语言中学到的知识和技能,可以通过外部的知识和工具来补全。比如Toolformer遇见一道计算题时会调用计算器,计算完成后把这个结果加入生成结果中。因此,对于语言模型的部分局限性,可以通过外部知识和技能对其进行增强。
再比如,2月微软研究院开展了连接物理世界的实验。它的基本思路是将ChatGPT作为一个强大的大脑安装在机器人上,让它通过自然语言的方式完成一系列任务。也可以通过这样的模型进行规划,把高层的指令转化为它的指令和动作。由此,机器人就可以进入物理世界。
3月15日GPT-4发布,其中一个重要的突破是多模态,它可以把文字图片结合起来,看图进行推理,这对人工智能来说是巨大的进步。我们终于有了一个多模态的,能够像人一样把不同的模态信息或者数据结合起来进行推理的模型。GPT4的逻辑性和准确性也有了极大提高,它在SAT(美国大学入学考试)和GRE测试中都拿到了很高的成绩。
3月16日,微软宣布GPT-4全面接入Office,大概年底就会发布。GPT-4接入Office办公软件后,我们就可以用自然语言要求它完成各种办公需求,比如在表格上做统计、做数据变换等。

3月23日,ChatGPT发布了它的插件商店,相当于要建立一个以大模型为中心的应用生态。现在商店里面已经有了不少插件,可以通过语言模型和外部插件工具配合,完成很多复杂的任务。
4月,自主智能体的概念出现了。它的基本思路是将大模型看作一个人脑,只要对任务进行描述,然后设定一些目标,剩下的事情大模型都可以自主完成。其中,代表性的工作包括AutoGPT,只需要对目标进行描述,它就会自主进行任务分解、执行、获取数据和分析等。另一项值得关注的工作是Generative Agents,通过大模型模拟25个智能体在小镇的生活,会产生很多复杂的社会行为。
很多人觉得大模型的发展速度太快,可能会有很多潜在风险。于是在3月22日,马斯克等人牵头签署了《暂停大型人工智能研究》公开信。但我认为大模型的发展脚步已经停不下来了,只会越走越快。
4月28日,政治局会议中首次提出了“通用人工智能”一词,指出“要重视通用人工智能发展,营造创新生态,重视防范风险”,说明我国对此事是高度重视的。
三、大模型的深刻影响
1、大模型可能带来的风险
1)虚假信息风险
大模型的造假能力非常强,我们难以辨别它生成的文字和图像的真实性。不过,现在有很多关于识别这种机器生成内容的研究。
2)价值观风险
任何大模型都有价值观倾向,比如ChatGPT就是西方左翼的立场。它之所以具有这样的价值观,是因为它学习的数据里大部分都是这样的观点。此外,在价值观对齐的时候,标准答案是以什么样的价值观来引导的,也决定了之后的模型会遵循什么样的价值观。
3)侵权风险
事实上,现在已经出现了这个问题。很多人起诉OpenAI,因为它未经许可就用了他们的数据,而对此法律上仍没有界定。此外,还有包括著作权主体在内的法律、制度、伦理道德等方面的诸多问题。
2、大模型可能产生的影响
1)对产业界的影响
当前各个科技企业都参与到百模大战之中,有望引发新一轮产业革命。
2)对学术界的影响
学界基本公认大模型是一个重大的技术突破,我们已经看到了通用人工智能的曙光。很多人工智能领域的研究,包括人工智能+的研究,都在发生根本性的变化。
3)从“不能用”到“能用”
长久以来难以解决的关键技术问题,比如语言理解、世界知识表述、复杂问题求解等,现在都有了巨大的突破。不仅所有传统任务都可以被显著改善,同时还打开了新应用的大门。
4)从“专用”到“通用”
大模型的泛化能力非常强,现在所有任务都可以转化为用自然语言表达、基于知识的问题求解。由于语言知识和问题求解能力的大幅提升,大模型变成了一个通用问题求解器,这为通用人工智能打开了一条可能的路径。大模型的泛化能力能够降低开发成本、提高开发效率,还可以在多任务之间进行共享,影响会非常深远。
5)从“体力劳动”到“脑力劳动”
现在的大模型就相当于一种人造大脑,它什么都知道,任劳任怨、一目千行、反应非常快,但有时候不太靠谱。如果在各个方面进一步提升,可能会出现一种超级智能,在很多能力上远超人类,比如我们做一些复杂问题求解时,只能调动很少的知识,而大模型可以调动很广泛的知识来做分析归纳和决策。由于看到了太多东西,它甚至可能会表现出一定的创造性,产生很多奇思妙想。在此背景下,大量重复性、知识依赖性的脑力劳动将被替代。
6)从数字世界到物理世界

当大模型有了多模态的能力,能够进行工具使用,有了机器身体,能够自主规划完成任务,它将成为一个真正的生命体进入物理世界。
7)自然科学实验
卡内基梅隆大学用大模型做了智能代理和自主智能体的实验。基于大预言模型的智能代理系统,可以自动设计、规划和执行科学实验,最后合成布洛芬、阿司匹林等。
8)社会科学实验
我们做了一个模拟器,通过大语言模型赋能智能体,智能体可以进行各种角色扮演,并进行交互,产生很多复杂的社会行为。对于以前的社会科学难以进行的实验,可以通过大规模地采用智能体来模拟人类社会行为进行实验,这将会对社会科学产生深刻影响,使其变成一门实验科学。
之所以要开发出我们自己的玉兰系列大模型,是因为我认为人工智能必须要Know-how,要知道整个大模型从头到尾的所有细节。我们将自己的大模型作为研究平台,支撑了很多人工智能领域的研究和实践。
总结来说,尽管大模型还存在着很多的局限性,但它为通用人工智能指出了一条可能的发展路径。人类经过六七十年的艰苦探索,终于找到了这样一条通用人工智能的可用路径,一定要去拥抱它。它可能是一种新的超级智能,对于各个领域必将产生深刻的影响。
论坛第二单元,结合CMF中国宏观经济专题报告,各位专家围绕“大模型未来的发展方向、人工智能的发展对经济的意义”等问题展开讨论。

复旦大学人工智能创新与产业研究院院长,阿里巴巴原副总裁漆远指出,大模型不仅能更好地泛化,而且能更好地推动产业发展,提升用户交互水平。未来的发展方向可能是在场景中找到真正需要的产品,将产品与算法和工程化真正结合起来。
人工智能的发展可能会改变其应用落地的模式,未来,人工智能在金融、医疗、教育、游戏设计等行业应用落地的可能性非常大。从产业发展趋势上看,大模型与互联网行业发展的趋势类似,当前正处于商业模式探索阶段。实际上,它是一个生态系统,需要产业、高校、服务平台和资金的深度融合。

望正资本全球宏观对冲基金董事长刘陈杰认为,中国经济在疫情后逐步复苏,但未来一个阶段将面临来自房地产和地方政府投资两方面的趋势性压力。从基本面来看,当前实体经济投资回报率低于融资成本,房地产和地方政府投资这两个过去推动经济增长的主要力量缩减之后,提升实体经济投资回报率和提高劳动生产率就需要在供给层面下工夫,特别是需要开展新一轮供给侧结构性改革。人工智能将成为供给侧结构性改革2.0版本,特别是在全要素生产率方面,人工智能将发挥不可替代的作用。
从时间维度上看,由于人工智能的准确性有待提高,因此对各个行业的替代是有时间层次的。预计它在准确性要求较低的行业和场景将落地较快,对准确度要求更高的应用和行则业需要进一步调试和时间,中短期内,AI将更多地作为辅助工具。
对于大模型应用落地的三点判断:1)本轮人工智能创新周期可能快于互联网周期;2)人工职能的硬件、软件及应用将在产业领域不断深化,应用生态将不断拓展,从而系统性推动人工智能大模型的发展;3)人工智能的发展可以分为三步,第一步是完成硬件基础设施建设,第二步实现重要应用落地,第三步是将其广泛应用于生产生活的各个环节中,当前中国正处于向第二步迈进的阶段。

北京大学计算机学院教授、人工智能研究院副院长黄铁军指出,大模型以联结主义和神经网络学派为基本支撑,试图建立一个神经网络,能够通过给出训练数据,建立输出和输入间的映射关系。大模型的特点包括规模大、涌现性和通用性。当网络参数达到数百亿时,大模型就成为了一个复杂系统,会像其他的物理系统一样产生“涌现”现象,出现融会贯通的能力。
大模型开启了智业革命的时代,纵观人类历史,只有工业革命和电力革命可以与之相提并论。未来3年,视觉、听觉、具身、行动等通用智能的技术路线也会出现,并且影响会更大;未来10年,智力革命会广泛普及,它将构建一个全新的生态体系,而开源开放将成为联合各方的基本方式;未来30年,智能将发展为以时空环境驱动的具身智能,能够进行实时感知、实时决策、实时行动。

浙商证券首席经济学家李超指出,本轮反垄断过程促进了产业科技革命的过程。人工智能企业将成为未来十到二十年间反垄断的最大受益者,这有助于人工智能领域的技术发展。
人工智能驱动的科技革命将极大降低主权债务危机和战争的风险。从微观层面来看,人工智能将提升企业资本回报率,解决企业层面的债务危机;从宏观层面来看,以人工智能为代表的科技革命将推动经济发展,使企业能够积累更多财富,进而增加国家税收,极大地降低主权债务风险。总体而言,人工智能为代表的第四次工业革命可能使经济全要素生产率呈现前期稳定、后期明显提升的趋势。
京东集团副总裁沈建光指出,京东以数据供应链为核心优势,信息链条非常长,在此背景下,人工智能大模型的应用可以显著提高产出并降低成本。当前,京东拥有言犀人工智能开发计算平台,可以在包括宣传、营销、物流控制等各个方面为中小微企业提供高效、低成本的AI产品和服务。未来,诊断可能会成为人工智能和大数据模型非常有前途的应用方向之一。
本文首发于微信公众号:中国宏观经济论坛 CMF。文章内容属作者个人观点,不代表和讯网立场。投资者据此操作,风险请自担。
继续浏览有关 人工智能 的文章
猜你喜欢
AI时代下的全新画质体验,海信电视E7N做到了么?

在人工智能技术飞速发展的今天,AI已经不仅仅是一个概念,而是开始真正融入并改变我们的日常生活。在电视行业,AI技术的应用正带来前所未有的画质体验。海信电视E7N,作为AI时代的先行者,通过其独特的技术优势,正在重新定义电视画质的新标准。...
Tag:人工智能通信行业周报:三折叠屏引领消费电子潮流,AI+终端发展有望提速

(以下内容从上海证券《通信行业周报:三折叠屏引领消费电子潮流,AI+终端发展有望提速》研报附件原文摘录) 周行情 行情回顾:过去一周(2024.9.2-9.8),上证指数、深证成指涨跌幅分别为-2.69%、-2.61%,中信通信指数涨跌幅为...
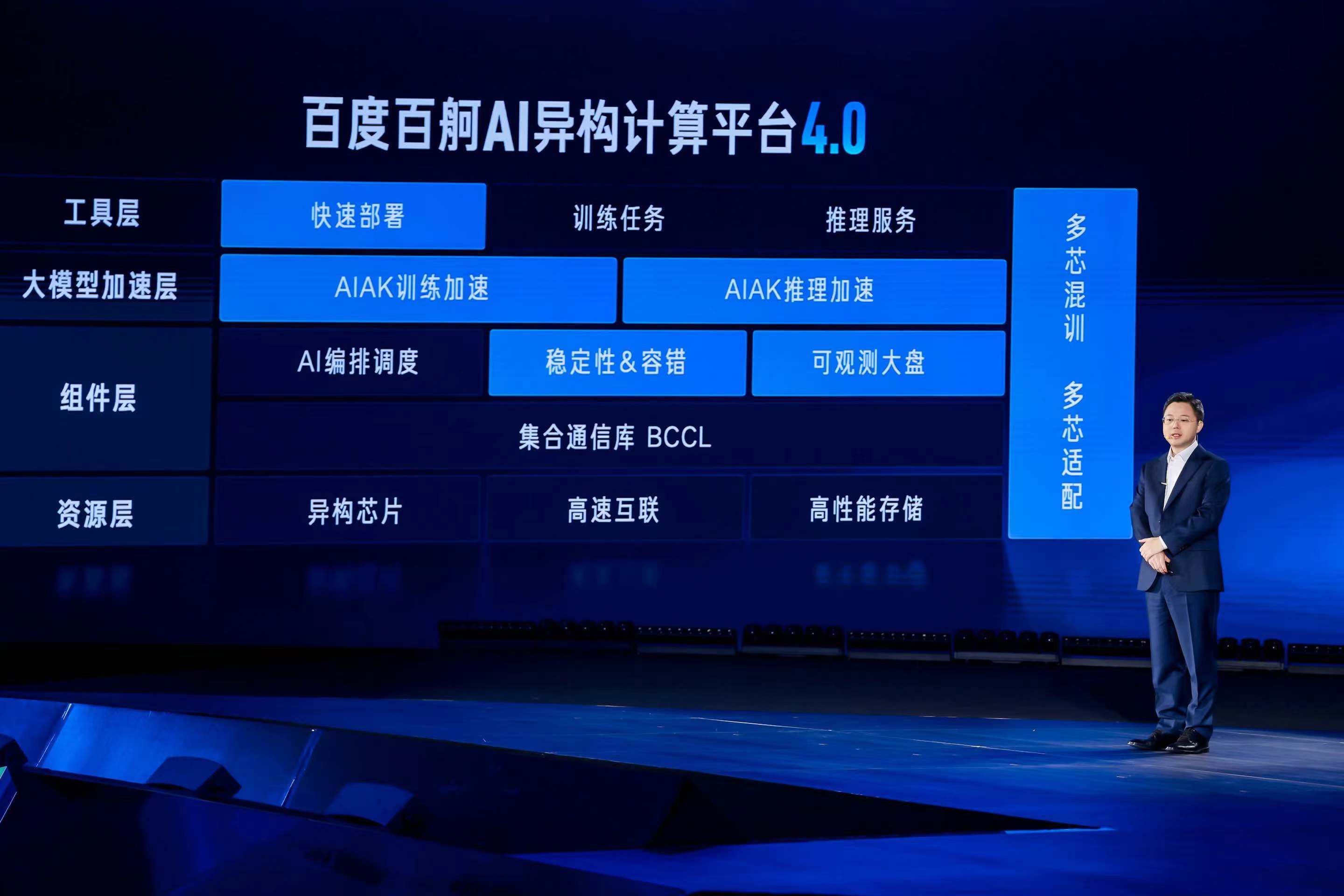
Tag:人工智能从“可用”到“好用”,百度智能云如何做大模型的“超级工厂”?
存储2024H1财报:行业上行带动高增长,新品搭上AI成驱动力
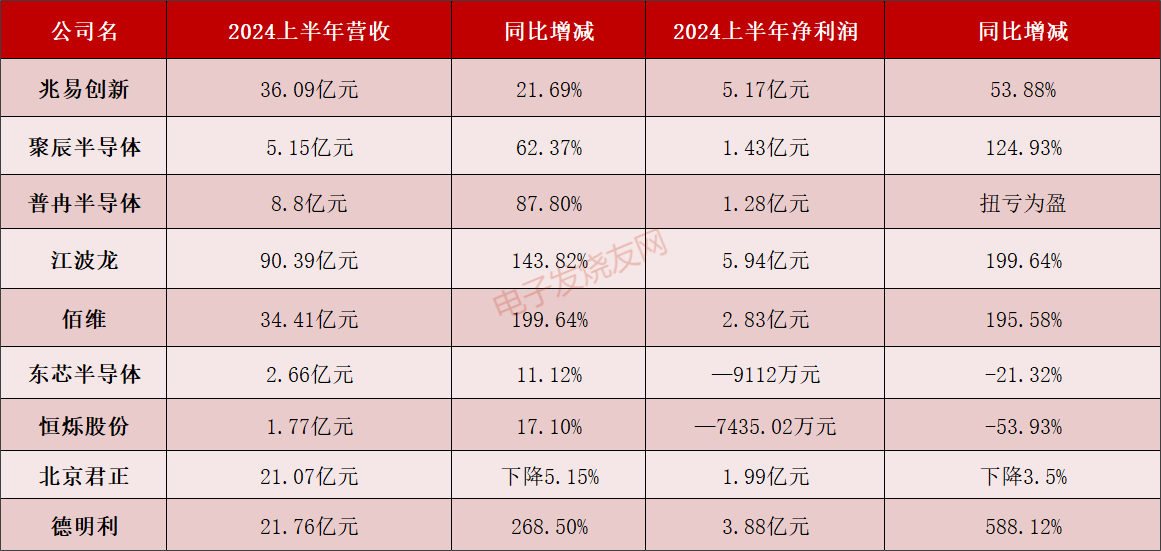
电子发烧友网报道(文/黄晶晶)自2023年第三季度开始,存储产业逐渐由之前的厂商亏损、大幅减产、需求不振等低迷行情,转变为步入复苏的上行周期。在我们之前跟踪的2023年第四季度以及2024年第一季度财报中已显现出这种向好的趋势。最近,国内...
Tag:人工智能人形机器人新品大爆发!突破关节极限,AI融合跨过“聪明”难关,进入万元阶段
